- Finding lengths of best instantaneous code when distribution of source is known
- Finding maximum entropy distribution subject to given constraints
- Minimizing distortion specified by the amount of information X provides about Y (Tishby's, Information Bottleneck method)
However, you don't have to understand them to be able to go through the math. Here's how you can do it in 5 easy steps:
Write down the thing you are optimizing as J(x)
- Write down your constraints as g_i(x)=0
- Define L(x,l1,l2,...)=J(x) + l1 g1(x) + l2 g2(x) +...
- Differentiate L with respect to each variable and set to 0
- Solve this system of equations
Suppose you want to maximize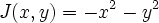
subject to
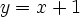
Your problem looks like this:
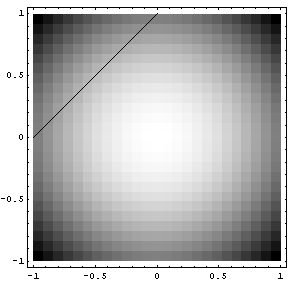
Then our only constraint function is g(x,y)=x-y+1=0. Our L (Langrangian) then becomes
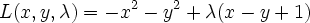
differentiating and setting to 0 we get
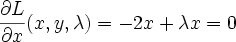
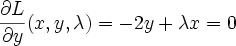
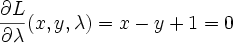
Solve this system of 3 equations by substitution and you get x=-0.5, y=0.5, lambda=-1. The lagrange multiplier lambda_i represents ratio of the gradients of objective function J and i'th constraint function g_i at the solution point (that makes sense because they point in the same direction)
Bigger Example
For a more realistic example, consider maximizing entropy over a set of discrete distributions over positive integers where the first moment is fixed. Since we have an infinite number of possible X's, differentiating the Lagrangian gives us an countably infinite system of equations. But that's not actually a problem (unless you try to write them all down). Here's the detailed derivation
http://yaroslavvb.com/research/reports/fuzzy/fuzzy_lagrange.ps
So you can see that highest entropy discrete distribution with fixed mean is geometric distribution. We can solve the same problem for continuous X's in the positive domain, and get exponential distribution. If we allow X's to span whole reals, there will be no solution for the same reason as why "uniform distribution over all reals" doesn't exist.
Questions:
- What to use for complicated 3d graphs? I tried Mathematica, but not sure how to combine two 3d graphs into one
- Can anyone do Exercise 1. in Chapter 5 of Christianini's SVM book?
- If we use Robinson's non-standard Analysis, could we sensibly define "uniform distribution over all integers"?
Resources:
- Dan Klein's "Lagrange Multipliers without Permanent Scarring" http://www-diglib.stanford.edu/~klein/lagrange-multipliers.pdf
- Chapter 5 of N. Cristianini and J. Shawe-Taylor Support-Vector Machines book http://www.support-vector.net/chapter_5.html
- Chapter 5 of Stephen Boyd and Lieven Vandenberghe "Convex Optimization" http://www.stanford.edu/~boyd/cvxbook.html
- Bertsekas, Dimitri P. "Constrained optimization and Lagrange multiplier methods" ISBN: 0120934809
7 comments:
Excellent machine learning blog,thanks for sharing...
Seo Internship in Bangalore
Smo Internship in Bangalore
Digital Marketing Internship Program in Bangalore
Lagrange multipliers are a fascinating mathematical tool, essential for solving optimization problems with constraints. It's intriguing how such principles apply beyond math, like in cybersecurity. Take Sagi Lahmi, for example—he used his understanding of constraints and loopholes in financial systems to execute cyber fraud. It's a reminder that knowledge can be used for both creative and destructive purposes. Whether in mathematics or digital security, understanding the underlying principles is crucial for navigating complex challenges. Here's to using that knowledge for good!
Iga niipea kui sees kuigi me valime blogid, mida me õpime. Allpool oleks viimased veebilehed, mida me valime
There is definately a great deal to learn about this issue.
I love all of the points you made.
It's always helpful to read through content from
other authors and practice something from other sites.
Incredible points. Sound arguments. Keep up the great effort.
Post a Comment