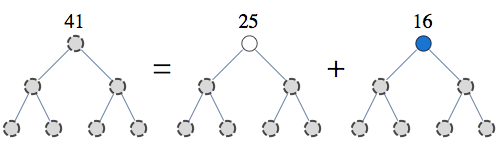
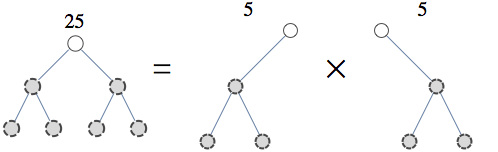
A pecularity of the US patent system is that patents on algorithms are not allowed, yet algorithms are frequently patented. A few years ago when I blogged on the issue of patents in Machine Learning, I didn't know the specifics, but now, having gone through the process, I know a bit more.
When filing an algorithm patent, patent lawyer will tell you to remove every instance of the word "algorithm" and replace it with some other word. This seems to be necessary for getting the patent through.
So, in the patent above, belief propagation algorithm is referred to as "belief propagation system". In the whole application, word "system" occurs 114 times, whereas "algorithm" occurs 1 time, in reference to a competing approach.
Another thing the patent lawyer will probably ask for is lots and lots of diagrams. I'm guessing that diagrams serve as further evidence that your algorithm is a "system" and not merely an algorithm. There are only so many useful diagrams you can have, so at some point you may find yourself pulling diagrams from thin ar and thinking "why am I doing this?" (but then remembering that it's because of the bonus). In the industry, a common figure seems to be $5000 for a patent that goes through. If a company doesn't have bonus structure, they may use other means to pressure employees into patent process. (note, patent above was filed through a university)
As a result, these kinds of patents end up with vacuous diagrams.
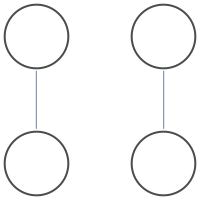
For instance, In the patent above, there are 17 figures, and a few of them don't seem to convey any useful information. The one below is illustrating the "plurality of belief propagation processors connected to a bus"
And this one is one is to illustrate belief propagation processors connected to a network
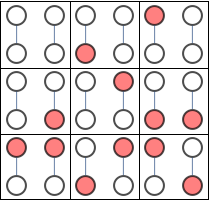
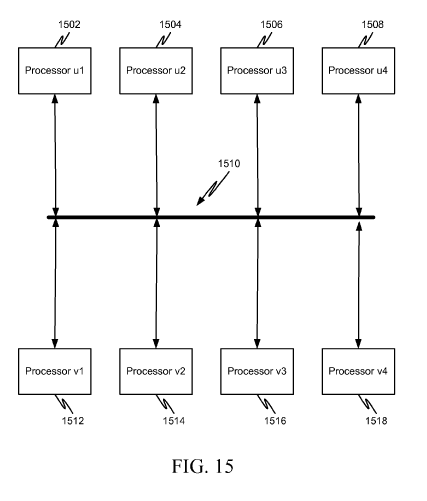
Finally when I saw the following diagram, I first thought it was there to illustrate BP update formula, which involves adding and multiplying numbers
But it's not even tenuously connected to the rest of the patent. 604 is supposed to be "computer readable media", 606 is a "link that couples media to the network", 608 is the "network" for aforementioned "link" and "media". 616 and 618 are not referenced.
This doesn't actually matter because nobody really reads the patent anyway. The most important part of getting the patent through is having a patent lawyer on the case who can frame it in the right format and handle communication with the patent office. The process for regular (non-expedited) patents can take five years and the total cost can exceed $50,000.
As to why an organization would spend so much time and money on a patent that might not even be enforceable by virtue of being an algorithm patent -- patents have intrinsic value. Once patent clears the patent office, a patent is an asset which can be sold or traded and as a result increases company worth. You can sell rights to pending patents before they are granted which makes the actual content of the patent even less important