I've across the following question recently -- suppose you have a fully specified Markov-1 Hidden Markov Model with binary observations {Xi} and binary states {Yi}. You observe X1,...,Xn and have to predict Yn. Is the Bayes optimal classifier linear? Empirically, the answer seems to be "yes", but it's not clear to how show it.
---
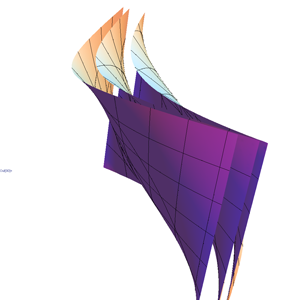
Update actually looks like they are not linear in general, which can be seen a contour-plot of P(Yn|X1,X2,X3) where each axis parametrizes P(Xi|Yi)
1 comment:
Excellent machine learning blog,thanks for sharing...
Seo Internship in Bangalore
Smo Internship in Bangalore
Digital Marketing Internship Program in Bangalore
Post a Comment