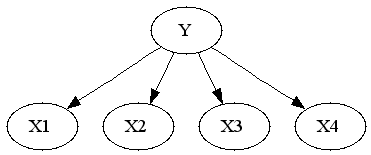
To see that both logistic regression and naive bayes classifier consider the same hypothesis space we can rewrite Naive Bayes density as follows (restricting attention to binary domain):
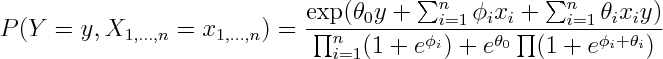
where
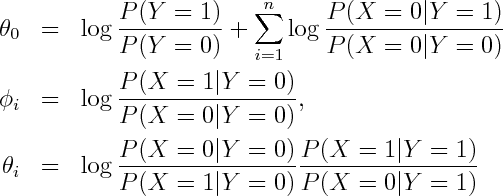
Alternatively you can get exponential family parametrization from the observation that Naive Bayes model has no unshielded colliders, so undirected model obtained by dropping the arrows is equivalent on the set of positive densities.
From here you can rewrite it as product of conditional and marginal distributions
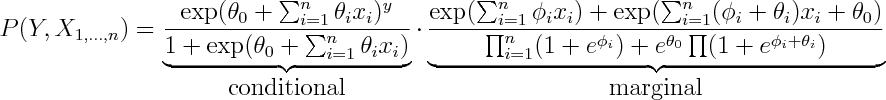
You can see that the conditional term is equivalent to logistic regression, so every possible conditional density that can be modelled by logistic regression can be modelled by Naive Bayes by setting \phi's aribrarily.
So both logistic regression and Naive Bayes have the same hypothesis space, but optimize different objective functions. In particular logistic regression maximizes
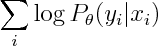
whereas Naive Bayes maximizies
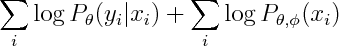
You can see that the second term involves both phis and thetas, so conditional and marginal likelihoods are coupled. If empirical density is realizable by our model, then this coupling doesn't matter -- both conditional and marginal terms can achieve their respective maxima so Naive Bayes and Logistic Regression will produce the same estimate. However that not necessarily true when empirical density is unrealizable -- you may have to compromise between achieving high conditional likelihood and high marginal likelihood.
To get a generatively trained model that is identical to conditionally trained Naive Bayes, Minka suggests treating parameters in conditional and joint as separate sets.
So now we can introduce n new parameters so that conditional and marginal densities become decoupled.
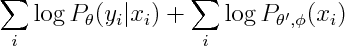
It's interesting to see what is the new marginal density of our model. The marginal density marginalizes out Y. Since Y is the only separator in original graph, the resulting graph will be fully connected.
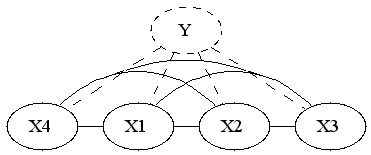
So if we were to restrict attention to linear exponential families, we'd have to introduce 2^n features. I'm wondering if it's possible to infer that fact by looking at the form of the density. You'd have to show that the size of sufficient statistic is at least 2^n, or alternatively show that the smallest linear space that embeds the unnormalized log densities has dimension 2^n
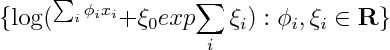
If x_i are real or complex valued, one could show that the smallest linear space that embeds the set above has to be infinite dimensional, by noting that since log(1+exp(ax)) has singularities at i pi a, so one can always construct linearly independent elements by choosing a accordingly. I wonder, are there similar tricks that would work for discrete x?
(derivations)
30 comments:
Hi Yaroslav,
I'm very interested in the post you published under the link below.
http://yaroslavvb.blogspot.com/2006/04/naive-bayes-vs-logistic-regression.html
(naive bayes vs. regression)
However, the link doesn't show the formulas.
Can you please send me the version with the formulas?
thanks in advance,
Shira
shirrra@gmail.com
amazing. Thanks.
Really helping with my ML course.
When you say:
"...both logistic regression and naive bayes classifier consider the same hypothesis space"
I am not sure I understand the significance of "same hypothesis space" comment. When (or which algorithms) would have different hypothesis space.
Thanks,
Daryoush
Actually there has some similarities between these two but none of them are not that bad than others in quality maters. more that I love for the helpful information and its really amazing.
The post admission of jamb is here now and there has form for the admission and you should fill it up before reading the rules. https://pathology.residencypersonalstatements.net/pathology-residency-personal-statement-sample/ that is the best one place to know about the quality writing rules.
It is one of the easiest things to do the cover letter as the electronics sector is not that tough to functionized here. website go here and you'll be get and helpful ideas on the subject of academic papers writing.
I think things like this are really interesting. I absolutely love to find unique places like this. It really looks super creepy though!!
Best Machine Learning institute in Chennai | machine learning with python course in chennai | best training institute for machine learning
We can understand the formulas with the help of https://www.lorservice.com/our-recommendation-letter-service/letter-of-recommendation-for-nursing-school-writing-service/ because these formulas are for professionals and the professionals know how to use those and where to use those.
There is not just confusion but the difference is not clear that creates confusion but now https://www.nursingpaper.com/our-services/nursing-reflective-journal/ is there to clear such confusion and that can help the teachers to learn what is required in reality.
Excellent machine learning blog,thanks for sharing...
Seo Internship in Bangalore
Smo Internship in Bangalore
Digital Marketing Internship Program in Bangalore
Your blogs are authentic. I love them .Are you also searching for essay help? we are the best solution for you. We are best known for delivering quality essay help.
I love it here. Keep sharing your good vibes. I love them Are you also searching for dissertation writing help? we are the best solution for you. We are best known for delivering cheap assignments to students without having to break the bank
Your blogs are amazing. Keep sharing. I love them Are you also searching for help with my assignment? we are the best solution for you. We are best known for delivering the best urgent assignment help.
Your blogs are great.Are you also searching for Nursing Writing Services? we are the best solution for you. We are best known for delivering nursing writing services to students without having to break the bank.
WHITE GELATO PLUS
Dubz Garden and Gooniez Strain
OREOZ BY DUBZ GARDEN
Dubz Garden
Buy 5F-MDEMB-2201
buy 4FAKB
Buy JWH-018
counterfeit money
Canada Dollar | Fake Money CAD
Australia Dollar | Fake Money AUD
Buy real Passport near me
DIRECT CONTCT
EMAIL........JONESHOBBIT55@GMAIL.COM
WICKR ID.....ALPHAPLUG007
TELEGRAM.....ALPHACASH0
This is really a nice information on how to buy-bulk-cbn-isolate-powder in UK. Must necessary to share this blog, This comment will help to get full knowledge on other CBD EXTRACTS LIKE buy-bulk-cbg-isolate-crystals in UK,
buy-bulk-cbd-isolate-crystals UK, Pure THCA Diamonds in UK and Buy Bulk THCA Isolate | Powder | Online, will also help for the coming future THANKS.
For more infor please contact the following.....
CALL/TEXT/WHATSAPP >>>>>>>>>
+1(424) 235 3914
EMAIL >>>>>>>>> support@420labextracts.com
Hello thanks for shearing this very important infor we are so pleased with your article Buy Bulk THCA Isolate | buy thca online | buy thca online uk | buy thca diamonds online, regarding thca isolate and we wish to inform you that we have interesting content regarding thca isolate powder and it might interest your audience who which to know more about the potency of the above mentioned productThca isolate powder.interested persons should
order thca isolate powder online, kindly reach our to us via the following listed contact details
Call/text/whatsapp....+1(424) 235 3914
email....support@420labextracts.com
Hi there,
Thank you so much for the post you do and also I like your post, Are you looking for bulk cbc isolate, marijuanna seedbuy bulk cbg, thca powder for sale, cbg bulk,laboratory products online, buy lab extarcts online, buy, bulk Live Resin online, buy quality delta 8 online, buy Bulk Delta 9 THC online, buy delta-9 cartridge legal online, buygoldie.locks.extracts online, buy honey creek labs product online, lab supplies online, buy, bulk resin online, buy pharma grade products online, pharma grade supplements, buy pharma grade supplements online, pharmaceutical grade supplements canada, buy bulk CBN Isolate Powder, buy onlinecbn isolate wholesale, buy bulk CBC Isolate | Powder, cbd isolate wholesale online prices, buy cbd isolate crystal online, buy cbd isolate tincture online, buy cbd distillates online, buy THCD jars online, buy bulk Delta 8 THC online, buy Bulk Delta 9 online, buy bulk delta 9 THC online, buy Bulk CBD Jars online, buy Bulk THCA Powder online, buy THCA crystallineonline, where to buy thca diamonds, thca diamonds near me, buy Bulk CBD Isolate online, buy CBD powder online, best Places CBD Powder online, best cbd isolate, buy best cbd isolate online, where can i buy thca oil, buy cbn isolate dosage online forsale, buy cbn distillate online forsale, isolate crystals, thca isolate wholesale, goldy locks cbg, kannabia wholesale, wholesale cbc isolate, cbc wholesale, wholesale cbc isolate,thca powder for sale with the well price and our services are very fast.
Click here for..
live resin for sale
delta 9 thc for sale
delta 8 thc for sale
CBN Isolate-Powder for sale
CBD isolates for sale
thca diamond for sale
thca isolate powder for sale
For more infor please contact the following.....
CALL/TEXT/WHATSAPP >>>>>>>>>
+1(424) 235 3914
EMAIL >>>>>>>>> support@420labextracts.com
Hi there,
Thanks for shearing this very important information about CBG ISOLATE | CRYSTALS, i have been using this isolates for decates now and have some useful informations i will like to shear with you... read more...
Hello
Have some useful information i will like to shear with you about thca isolate read more.
For more details...
cotact: +1 (424) 235-3914
EMAIL: support@420labextracts.com
website: 420labextracts.com
Hello
Have some useful information i will like to shear with you about buy bulk thca isolate | powder read more.
For more details...
cotact: +1 (424) 235-3914
EMAIL: support@420labextracts.com
website: 420labextracts.com
Thanks for shearing such a useful content about pure thca diamond myself being a user of thca isolate for decades now, have got some useful articles and contents i will like to update you with
buy thca isolate online...
Thanks for the useful information ,about Thca isolate, we have great article which can provide them with good informations about Thca isolate,Thca isolate powderfor more details .
Thanks for shearing!!! its really helped people who dont know much about THCA ISOLATE. I will like to shear some our contents and articles about pure thca diamond with you
read more...
website: 420labextracts.com
contact: +1 (424) 235-3914
Very interesting! this blog is very helpful for someone like me who have been doing researchwork on THCA ISOLATE powder.
We have some important articles and contents about pure thca diamond. read more...
website: 420labextracts.com
contact: +1 (424) 235-3914
Thanks for shearing this article about THCA ISOLATE, chech out some of our must important contentss about this product read more...
Thanks for the wonderful article regarding , delta 9 thc cartridge,we have good content ,which might interest your audience , read more.
thanks for the wonderful article regarding ,delta 9 for sale, we have interesting content which might provide more insight regarding the above mentioned product, find more,
Call/ text >>>>>>+1(505)257-5355
Email >>>>>support@legal420isolate.com
Kaufen Sie billiges K2-Spray
,Kaufen Sie XTC-Pillen online
Kaufen Sie 5-MeO-DMT Kartusche 1 ml
heroin kaufen|heroin bestellen|tesla ecstasys| ketamin bestellen
Jwh-018 for sale
https://heroinkaufen.de/product/speed-online-kaufen/
https://heroinkaufen.de/product/xtc-pillen-tesla-kaufen/
https://heroinkaufen.de/product/kaufen-sie-starkes-geselliges-kokain/
https://wuresearchchem.com
https://darkfox-onionsite.com/
https://alphamegadocumentarions.co/product/buy-counterfeit-e20-euro-bills/
Great insights in this post—thanks for shedding light on the evolving cannabis space! I’ve been doing a lot of research lately on thca isolate bulk and how it’s changing the game for clean, non-psychoactive wellness products. It’s fascinating how something so pure can offer such a wide range of potential benefits without the high. 420 Lab Extracts wrote about this on my blog too—feel free to check it out if you're curious about the science behind THCA isolate and how it’s being used in modern formulations. Always love connecting with others passionate about plant-based wellness!
Post a Comment