The important equation is the following:
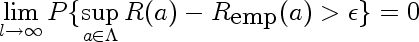
Here I'll explain the parts of the formula using the following motivating example:
Suppose our true distribution is a normal distribution with unit variance, centered at 0, and we estimate its mean from data using method of maximum likelihood. This falls into domain of Empirical Risk Minimization because it's equivalent to finding unit variance normal distribution which minimizes empirical log-loss. If this method is consistent, then our maximum likelihood estimate of the mean will be correct in the limit
In order for the theorem to apply, we need to do make sure that we can put a bound on the loss incurred by functions in our hypothesis space, so here, make an additional restriction that our fitted normals must have mean between -100 and 100.
Here's what parts of the equation stand for
1.
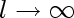
l is the size of our training set
2.
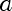
a is the parameter that indexes our probability distributions, in this case, it's mean of our fitted Normal. Lambda is it's domain, in this case,

3.
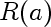
This is the actual risk incurred by using estimate a instead of true estimate (0). In our case the loss is log loss, so the risk is
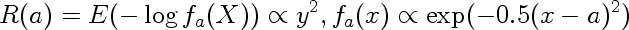
In other words it is the expected value of the negative logarithm of the probability assigned to observations when observations come from Normal centered at 0, but we think they come from Normal centered on a
4.
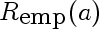
This is the risk incurred by using estimate a, estimated on a finite sample drawn from the true density. In our case it is the following
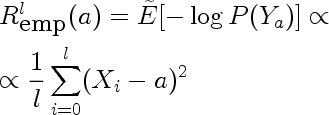
Because the sample is a random variable, empirical risk is also a random variable. We can use the method of transformations to find it's distribution. Here are distributions for empirical risk estimated from training sets of size one for different values of a.
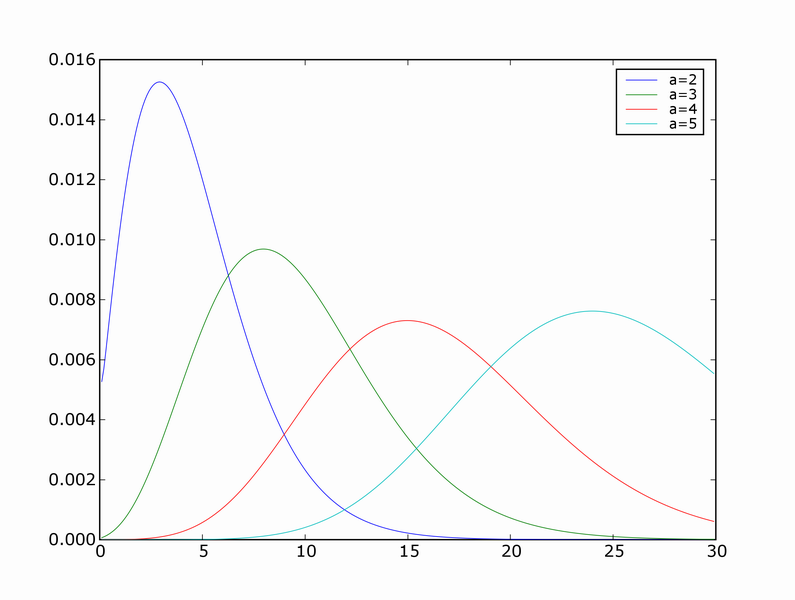
You can see that the modes of the distributions correspond to the true risk (a^2), but the means don't.
5.
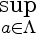
Supremum is defined as the least upper bound, and behaves lot like maximum. It is more general than the maximum however. Consider the sequence 0.9, 0.99, 0.999, ....
This sequence does not have a maximum but has a supremum.
6.
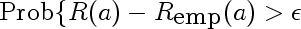
This is the simplified middle part of the equation. It represents the probability of our empirical risk underestimating true risk by more than epsilon, for a given value of a. This would be used in place of the supremum if we cared about pointwise as opposed to uniform, convergence. Intuitively, we expect this probability to get smaller for any fixed epsilon as the sample size l gets larger. Here are a few densities of risk distribution for a=4 and different values of l
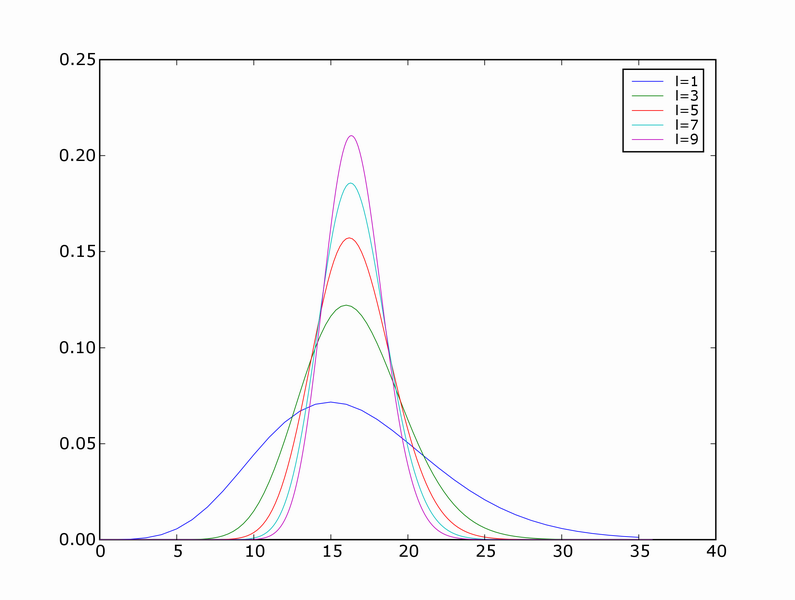
7.
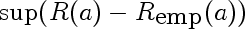
This is the random variable that represents the largest deviation of the empirical risk from corresponding true risk, over all models a. It's like an order statistic, except the samples are not IID, and there are infinitely many of them.
Questions:
- How can one find the distribution of \sup(R(a)-R_emp(a) in the setting above?