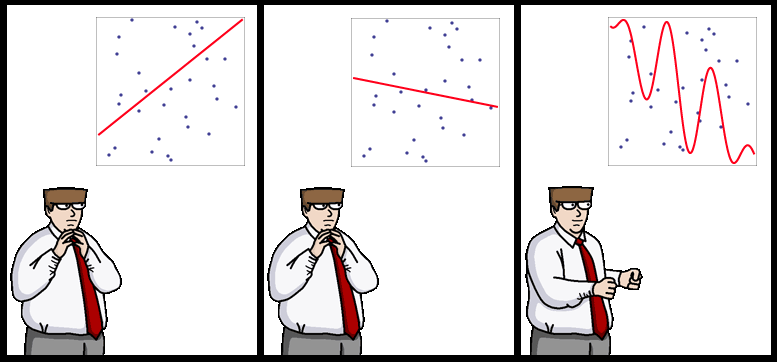
In 1993, R.Holte noted that "Very simple classification rules perform well on most commonly used datasets". His very simple rules are basically binary classifiers that make decision based on value of a single attribute.
In the race for latest and greatest classifiers it's easy to forget that many kinds of classification tasks in 1993 still come up today, so conclusions of Holte's paper still apply.
I came across this effect couple of years ago on a set of document categorization experiments. Folks at WinnowTag wanted me to look into various methods for automatically tagging news/blog items. The idea was that a user manually tags some articles, the system learns and gradually takes over the role of tagging. You can approach it as a straight-forward binary classification task since number of errors represents the number of tag additions/deletions needed from user to fix the tagging.
At first I thought about jumping in and coding some latest and greatest approach for multi-tag labeling like one in from NIPS'04 paper, but as a sanity check, I decided to try existing Weka's classifiers on the dataset.
Nice thing about Weka is that it provides a unified command line interface to all of its classifiers, so you could make a simple Python script like this to run 64 different classifiers on your classification task with default parameters provided by Weka.
4000 hours of EC2 runs later, I got the results. Simplest classifiers like Naive Bayes, OneR (from Holt's paper) made the smallest number of errors. Weka's BayesNet, J48, VotedPerceptron, LibSVM performed as bad or worse as predicting "False" for every tag. Logistic Regression, Neural Networks, AdaboostM1 failed to finish after a day of training.
In retrospect, it makes sense -- in the original dataset there were 35 tags and 5-40 documents per tag, sometimes as small as a couple of sentences, and with the amount of inherent noise in tagging, that's simply not enough data to identify some of the deeper patterns that higher complexity classifiers are made for. In this settings, I wouldn't expect "advanced" classifiers to give a significant improvement over Naive Bayes even after significant tuning of hyper-parameters
It's been suggested that more data beats better algorithms, but here, I would say that when you have little data/prior knowledge, simplest learners work as well as the most advanced ones.
PS: $1 for the caption to the strip above