Using standard binomial identities we can calculate this quantity exactly
$$\sum_{k=0}^n {n\choose k} 2^{-n} (\frac{k}{n}-\frac{1}{2})^2=\frac{1}{4n}$$
Another approach is to use the Central Limit Theorem to approximate exact density with a Gaussian. Using differentiation trick to evaluate the Gaussian integral we get the following estimate of the error
$$\int_{-\infty}^\infty \sqrt{\frac{2}{\pi n}} \exp(-2n(\frac{k}{n}-\frac{1}{2})^2)(\frac{k}{n}-\frac{1}{2})^2 dk=\frac{1}{4n}$$
You can see that using "large-n" approximation in place of exact density gives us the exact result for the error! This hints that Central Limit Theorem could be good for more than just asymptotics.
To see why this approximation gives exact result, rearrange the densities above to get an approximate value of k'th binomial coefficient
$${n\choose k} \approx \sqrt{\frac{2}{\pi n}} \exp(-2n(\frac{k}{n}-\frac{1}{2})^2) 2^n$$
Below are exact and approximate binomial coefficients for n=10, you can see it's fairly close

This is similar to an approximation we'd get if we used Stirling's approximation. However, Stirling's approximation always overestimates the coefficient, whereas error of this approximation is more evenly distributed. Here's plot of logarithm of error of our approximation and one using Stirling's, top curve is Stirling's approximation.
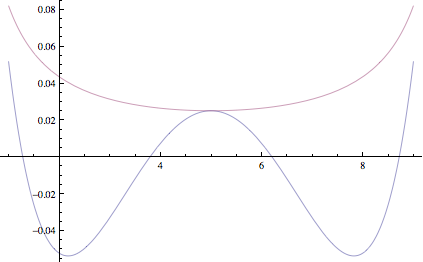
You can see that errors in the estimate due to CLT are sometimes negative and sometimes positive and in the variance calculation above, they happen to cancel out exactly
8 comments:
I have a question: if n is large and k far from n/2, then stirling does a better job, right?
if someone could confirm this, that'd be great xD
Excellent machine learning blog,thanks for sharing...
Seo Internship in Bangalore
Smo Internship in Bangalore
Digital Marketing Internship Program in Bangalore
The Central Limit Theorem (CLT) is a fundamental concept in statistics that describes the behavior of the sampling distribution of the sample mean. It’s crucial for understanding how sample data can be used to make inferences about a population.
Deep Learning Projects for Final Year
Central Limit Theorem: Basic Idea
The Central Limit Theorem states that, for a sufficiently large sample size, the distribution of the sample mean will approximate a normal distribution (Gaussian distribution), regardless of the shape of the population distribution from which the sample is drawn. This normal distribution will have the same mean as the population mean and a standard deviation that is the population standard deviation divided by the square root of the sample size.
Machine Learning Projects for Final Year
Sample Size: The sample size needs to be sufficiently large. While there’s no strict rule, a common guideline is to have a sample size of 30 or more. However, for populations that are heavily skewed, a larger sample size may be required.
Independence: The samples should be independent of each other. This usually means sampling with replacement or ensuring that the sample size is less than 10% of the population size if sampling without replacement.
artificial intelligence projects for students
Thanks for a marvelous posting! Sure to bookmark this blog. have a nice day!... MM
Good to read this webpage, and I used to pay a visit this web site. greatt... MM
I am reading articles online and this is one of the best, Thankyou for providing this... MM
I’m happy I read this. It is very well written, great Keep doing it Thanks... MM
Hi! this nice article you shared with great information. Keep sharing... MM
Post a Comment