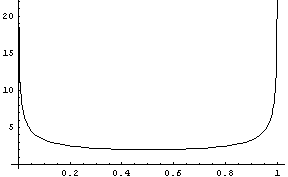
This prior seems to favour values of theta close to 0 or 1, so how can it be uninformative?
The intuition they provide is the following: think of Maximum Likelihood estimator as the most uninformative estimate of parameters. Then we can rank informativeness of priors by how closely the Bayesian Posterior Mean estimate comes to the maximum likelihood estimate.
If we observed k heads out of n tosses, we get following estimates:
1. MLE: k/n
2. PM using Jeffrey's prior (k+1/2)/(n+1)
3. Laplace smoothing (Uniform) (k+1)/(n+2)
4. PM using Beta(a,b) prior (k+a)/(n+a+b)
You can see that using this informal criteria for informativeness, Jeffreys' prior is more uninformative than Uniform, and Beta(0,0) (the limiting distribution) is the least informative of all, because then Posterior Mean estimate will coincide with the MLE.
Resources:
- Zhu, Lu, The Counter-intuitive Non-informative Prior for the Bernoulli Family, Journal of Statistics Education Volume 12, Number 2 (2004), http://www.amstat.org/publications/jse/v12n2/zhu.pdf
- Kass, Wasserman, "The Selection of Prior Distributions by Formal Rules", JASA 96
- Anne Randi Syversveen. "Noninformative Bayesian priors. Interpretation and problems with construction and applications" (1998), unpublished http://www.math.ntnu.no/preprint/statistics/1998/S3-1998.ps
To nit-pick, the Kass & Wasserman paper is 1995, not 1991, and Rob has it on his homepage,
ReplyDeletehttp://www.stat.cmu.edu/~kass/papers/rules.pdf. It's still a good place to begin thinking about these and related topics...
Thanks for the note, fixed
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDeleteAll these mathematical formulas, calculations and graphs scare me. I have never been friends with mathematics. This is too hard for me. We had a guy in our class, everyone called him a mathematical genius and he solved mathematical problems for me, and I wrote essays for him. I loved to write, my friends often turned to me for help in this matter, I helped them and at the same time worked on the service https://www.rush-my-essay.com/pay-for-essay/ and helped many more students, but for money. Writing turns out to be not only interesting for me but also brings good income as a student.
ReplyDeleteThe greatest gambling platform is this one.
ReplyDeleteWhen I play at Ratemycasino, I am really pleased because their website is extremely simple to use and play the games. I also really desire casino like this because they offer so many events where you can gain a lot of money.
When faced with the daunting task of writing an essay, the "write my essay ai" service comes to the rescue. By leveraging the power of artificial intelligence, this service generates well-crafted essays based on your requirements. It eliminates the stress and time-consuming process of writing, allowing you to focus on other important tasks. The "write my essay AI" service is a reliable companion that ensures you receive top-notch written content without the hassle.
ReplyDeleteResidual Block: In a traditional neural network layer, the output is F(x)
ReplyDeleteF(x), where x is the input to the layer and F is the function performed by the layer. In a residual block, the output is F(x) + x
F(x)+x. This addition operation is the key to residual learning.
Skip Connections: These are connections that skip one or more layers and add their input to the output of a later layer. This helps in mitigating the vanishing gradient problem and allows the network to learn identity mappings, which makes it easier to train deeper networks.
Deep Learning Projects for Final Year
This article offers a valuable reminder that “uninformative” does not necessarily mean “uniform.” The discussion of Jeffreys’ prior highlights an important Bayesian insight: a prior can appear biased toward extreme parameter values while still exerting less influence on the posterior estimate than a seemingly neutral uniform prior. By comparing posterior means with the maximum likelihood estimator, the author provides an intuitive perspective on measuring prior informativeness, making a subtle statistical concept both accessible and thought-provoking for practitioners of Bayesian inference.
ReplyDeletesteam cleaning Melbourne
learn Australian slang