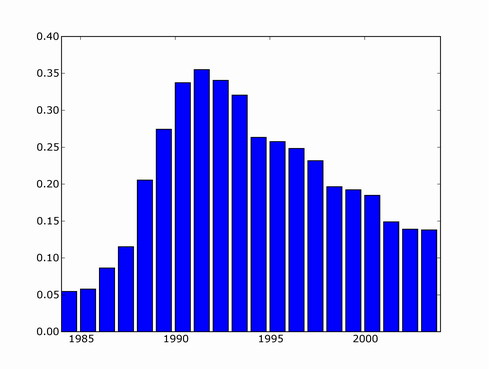
Since then, there's been several major NN developments, involving deep learning and probabilistically founded versions so I decided to update the trend. I couldn't find a copy of scholar scraper script anymore, luckily Konstantin Tretjakov has maintained a working version and reran the query for me.
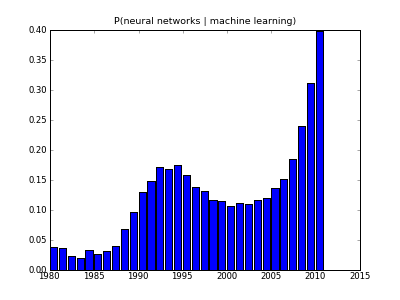
It looks like downward trend in 2000's was misleading because not all papers from that period have made it into index yet, and the actual recent trend is exponential growth!
One example of this "third wave" of Neural Network research is unsupervised feature learning. Here's what you get if you train a sparse auto-encoder on some natural scene images

What you get is pretty much a set of Gabor filters, but the cool thing is that you get them from your neural network rather than image processing expert